
Designs of Database System
Designs of Database System ——Paper++
《数据库基础》课程设计
1 设计目的
《数据库基础》课程设计是计算机科学与技术专业集中实践性环节之一,旨在让同学们加深对数据库基础理论和基本知识的理解,掌握设计数据库管理系统的基本方法,锻炼运用知识解决实际问题的动手能力。
2 任务与要求
要求学生从给定的设计题目中进行选择,进行需求分析,概念设计、逻辑设计,数据库设计;完成表结构、表之间关联,视图定义、触发器定义、索引以及安全性的实现;用SQL语句在SQLite系统中实现数据库的数据输入、查询、更新和输出;给出实现效果截图及部分测试结果。
3 个人文献管理系统—Paper++
3.1 引言
随着我在专业学习上不断的深入,以及个人兴趣的发展,我开始关注人工智能领域下的自然语言处理方向,决定将这个方向作为自己今后学习研究的主要方向,并且开始做一些基础的科研工作。在这些科研工作中往往需要阅读大量的学术文献,越来越多的文献使得这种简单的管理方式不足以满足我的要求。除此之外,想成为优秀的科研人员需要我养成定时阅读论文的习惯。目前市面上有一些论文管理软件如Octave、Endnote、Mendeley、Zotero等,但是其功能并不完全符合我的需求。于是我为自己设计了一个量身定做的个人文献管理系统Paper++。
3.2 需求分析
3.2.1 系统的主要任务
3.2.1.1 系统功能描述
总的来说,Paper++的主要任务包括整理论文和为定期阅读论文的功能。这需要实现论文、作者、关键词等信息的增删改查;实现完整论文列表的查看,手动选择论文的阅读优先级;实现论文信息的删除;实现论文信息的查找,允许按照标题、作者、关键词进行查找。
3.2.1.2数据库完整性要求
3.2.1.2.1实体完整性
Paper++共涉及到11个表,对所有表进行了主键id的设置。所有主键均设置为自增主键,即在每次插入新的数据后数据库引擎会自动增加1,删除数据行也不影响id。
3.2.1.2.3用户定义完整性
- Paper.read, read属性表示用户是否已经阅读过该论文,read列的取值只能为0和1,0表示没有阅读过,1表示已经阅读过。实际上可以将这一属性看作布尔类型。
- Paper.rank rank属性表示用户定义的论文的阅读优先级,rank初始值为0,用户可以将其值设置为1,2,3,4,5,数字越大代表优先级越高。
- Job.class class属性代表每个工作的类别,class属性只能为’University’, ‘Company’, ‘Institute’, ‘Hospital’, ‘None’中的一个。
- 在PLog,KLog,ALog,ReadLog四个日志表中均有entry_date属性。entry_date属性表示插入日志的时间,四个表中entry_date属性均被设置为非空(NOT NULL)
3.2.1.2.3 参照完整性
由于Paper++的数据库结构中涉及到多处多对多的联系,我采用了表A,表A2B,表B的形式进行表示,其中表A2B采用外键联系表A和表B。除此以外,部分日志表通过外键连接对应表以记录数据。所有的外键均遵从外键的要求:非空;指向的为某个表的主键。具体包括:
P2K表有pid和kid属性,分别对应Paper表和Keywords表的主键。
P2A表有pid和aid属性,分别对应Paper表和Authors表的主键。
A2J表有aid和jid属性,分别对应Authors表和Job表的主键。
PLog表有pid属性,对应Paper表的主键。
KLog表有kid属性,对应Keywords表的主键。
ALog表有aid属性,对应Authors表的主键。
ReadLog表有pid属性,对应Paper表的主键。
3.2.1.2.4 数据库安全性
考虑到实际情况,Paper++为文献整理、阅读软件,而涉及到的论文均来源于开放的学术数据库,不涉及到机密的问题,所以不设置用户角色,不进行角色授权。仅对论文的增删查改进行设置,所有的设置通过Python代码实现。
不对用户开放修改论文基本信息(标题、作者、摘要)的权限。
限制用户一次只能进行一篇论文的添加、修改或是删除,防止出现短时间内注入大量信息的情况。
不允许重复插入相同的论文、关键词等。
3.2.2 系统功能描述
系统的主要任务包括整理论文和为定期阅读论文的习惯提供帮助。具体分析如下:
3.2.2.1 添加论文模块
对于本地论文pdf文件,首先读取pdf文件,然后对信息进行处理,将部分内容展示给用户,由用户手动输入标题、作者、作者单位,其余信息由程序自动提取。对于arXiv和PubMed两个来源的论文,采用爬虫技术从网页获取论文的信息并且直接下载论文。最后将论文信息插入数据库。对于所有论文,程序自动对摘要进行关键词的提取。
3.2.2.2 展示全部论文
从视图中中查询数据,并且对多对多的关系进行了整合,最终进行展示。
在此界面用户可以对论文条目进行删除,程序清除数据库中对应表中的信息。
同时,用户还可以对阅读优先级、阅读注释的编辑和修改,并将相应信息存入数据库。在此界面还可以点击按钮查看生成的关键词词云图。
3.2.2.3 查询模块
用户可以对标题、作者、关键词三个字段进行查询。其中论文题目中包含查询字段即可被检索到;而查询作者、关键词则必须拼写正确。所有的查询均实现了对大小写的兼容。
3.2.2.4 阅读论文模块
在此界面会按照优先级的顺序展示所有未读的论文,用户双击论文条目即可使用用户本地的pdf阅读器打开论文文件,Paper++不包含pdf阅读器。
在此界面用户还可以进行阅读论文的数量和提醒时间进行设置,Paper++实现按照阅读优先级推送论文,并展示与其相关性最强的论文题目。其中计算论文相关性通过深度学习的方法实现。
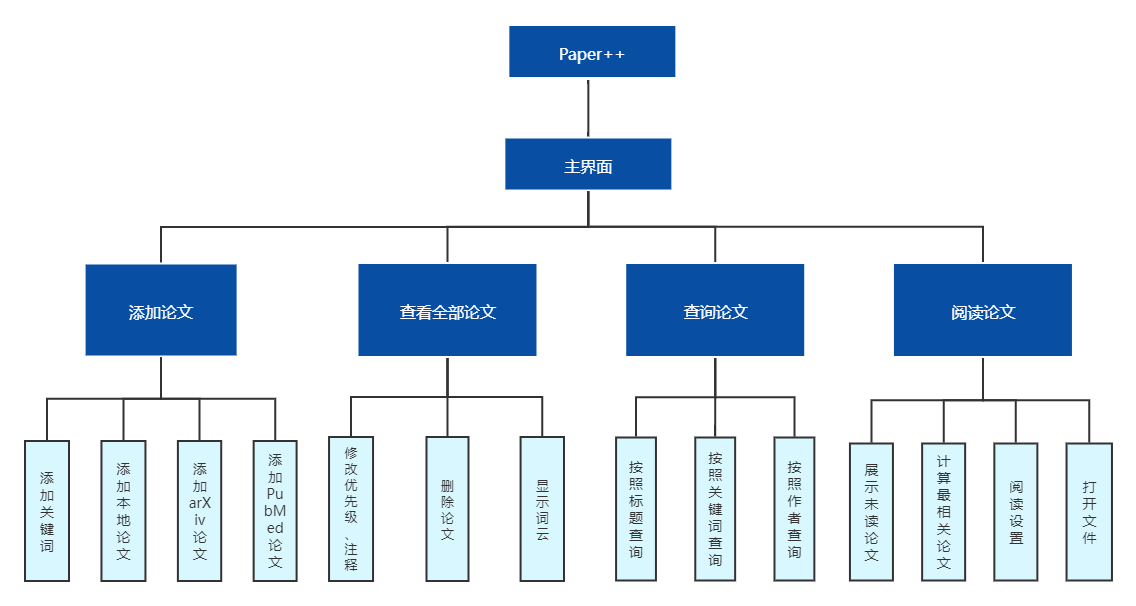
图3-1 Paper++功能模块图
3.3 概念设计
3.3.1 连接的设计
Paper++中涉及到了Paper(论文),Authors(作者),Keywords(关键词),Job(作者单位)四个主要的实体。这其中Paper和Authors,,Authors和Job,Paper和Keyowrds是多对多的联系,例如一篇论文有多个作者,而一个作者会参与多篇论文。Author和Job看似是多对一的联系,即多个作者工作工作于同一个单位,实际上这没有考虑到一些特殊情况。例如A在清华大学就读博士,毕业后在阿里巴巴工作,期间都有论文发表,那么A的单位就应该有清华大学和阿里巴巴两个,除此之外,还有一些作者有兼职的情况。
除此之外,我创建了四个表:PLog,Klog,Alog,ReadLog分别用来存储Paper插入。Keywords表插入,Authors表插入和用户阅读论文日志记录。其中用户阅读论文的日志只需监视Paper表中read属性即可实现。这些表与对应的主表一对一连接。
3.3.2 属性的设计
根据论文实际包含的属性和系统开发中实现功能所需要的属性,初步设计出各表的属性。其中四个日志表设置为弱实体集,不设置主键,仅用外键与对应的表连接。P2K,P2A,A2J为联系。
Paper:pid(id),title(论文标题), abstract(摘要),read(是否已阅读论文),rank(用户定义优先级),note(用户定义注释),path(论文在本地的存储路径),token(论文特征向量)
Keyword:kid(id),keyword(关键词内容)
Authors:aid(id),aname(作者名字)
Job:jid(id),jname(单位名称),class(单位类型)
PLog:pid(论文id),entry_date(时间)
ALog:aid(作者id),entry_date(时间)
KLog:kid(关键词id),entry_date(时间)
ReadLog:pid(论文id),title(论文题目), entry_date(时间)
P2K: id,pid(论文id),kid(关键词id),title, keyword
P2A: id,title, aname)
A2J: id,aname, jname
3.3.3 E-R图
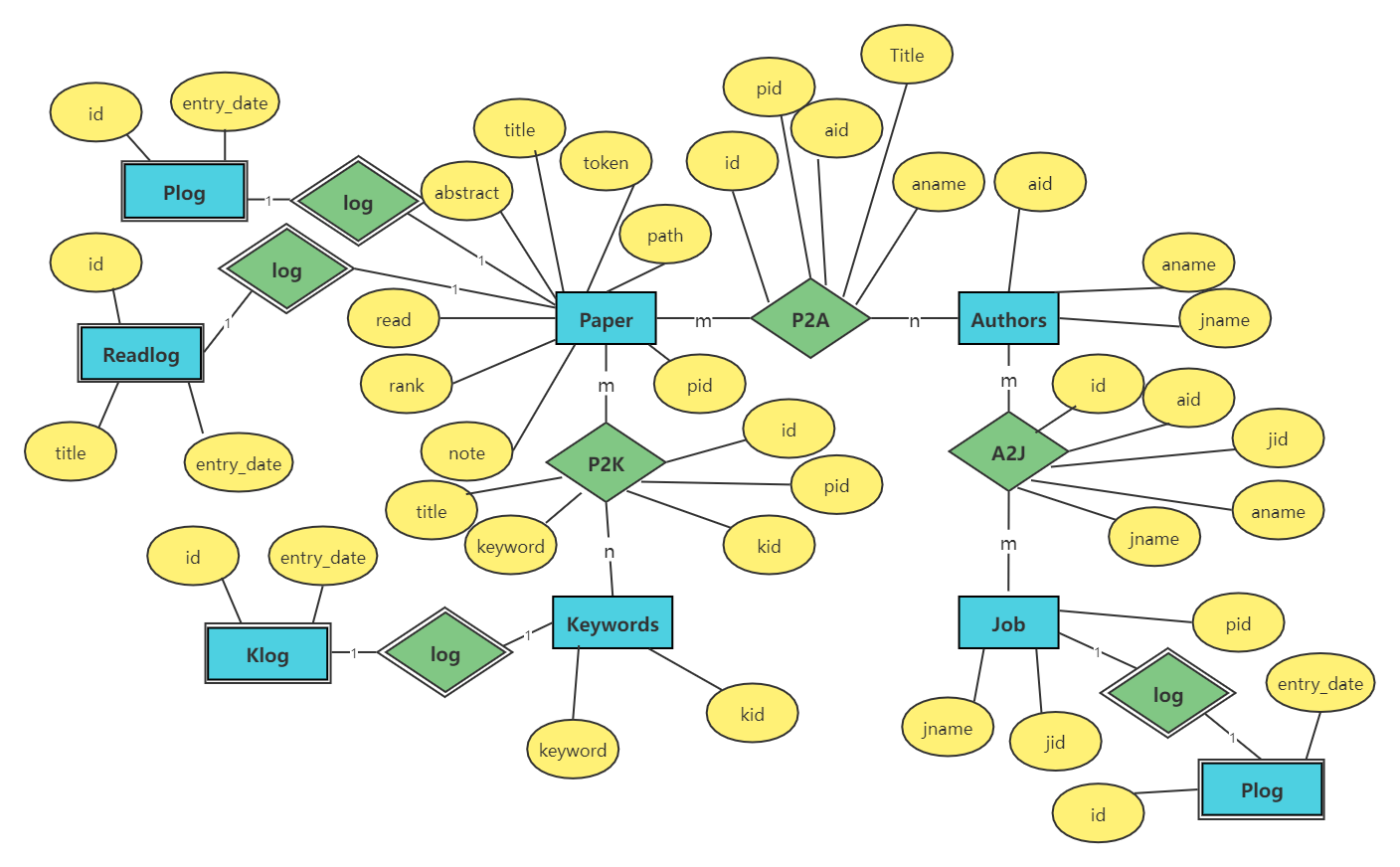
图3-2 Paper++ E-R图
3.4 逻辑设计
3.4.1 关系模式优化
分析Paper++涉及到的所有关系,对关系模式进行优化
3.4.1.1 合并关系
关系在设计时已经达到最简,没有可以合并的关系。
3.4.1.2 关系的连接
通过视图的形式进行连接,Paper++定义了两个视图,分别是Paper_info和Author_info。我在设计联系表的时候特意加入被连接表的一些属性,使得在创建视图的时候更加简单,不需要访问联系另一端的表即可获得需要的信息。
Paper_info连接Paper、Author、Keyword表,以获得所有关于论文的信息。具体包括Paper表的title、abstract、read、rank、note属性,P2K表的keyword属性,P2A表的aname属性。
Author_info连接Authors、Job、Paper表,以获得所有关于作者的信息。具体包括Authors表的aname、jname属性,A2J表的class属性,P2A表的title属性。
3.4.1.3 关系的分解
分析Paper++涉及到的关系可以发现,所有关系均不符合垂直分解和水平分解的要求,既不需要进行分解。
3.4.2 外模式的设计
- 视图的定义
上文所述的视图时直接面向用户的,Paper表中的path、token属性以及各个表的id信息没有被放入视图中,因为这些属性对于用户没有意义,是为了实现系统功能二存在的。
- 处理计算属性
Paper表中的token属性是计算属性,一篇论文的token是对其所有关键词的词向量求和,token的计算时间较长,计算一篇论文的token大约需要30秒。所以我将其在插入表时一次计算完成并且将其设置为一个属性直接存储数据,需要时直接读取数据,而不是每次需要使用token时都进行计算。这节省了大量的时间,提升了用户使用体验。
3.4.3 关系模式
根据E-R图可以得到强实体集Paper、Keywords、Authors、Job,弱实体集P2K、P2A、A2J,联系集PLog、ALog、KLog、ReadLog的关系模式,整理得到完整的关系模式:
Paper (pid, title, abstract,read,rank, note, path, token, author, keyword)
Keywords (kid, keyword)
Authors (aid, aname,jname, jclass)
Job (jid, jname, class)
P2K (id, title, keyword)
P2A (id, title, aname)
A2J (id, aname, jname)
PLog (pid, entry_date)
ALog (aid, entry_date)
KLog (kid, entry_date)
ReadLog (pid, title, entry_date)
3.5 物理结构设计
3.5.1 存取方法
Paper++的dbPaper数据库采用索引存取的方法,我在四个需要经常访问的表Paper, Authors, Keywords, Job上的id一列创建了索引。id列在查询中经常使用,且在创建视图的连接过程中被使用,所以符合创建索引的要求。
3.5.2 存储结构
考虑到实际情况,我将所有的表放于和程序代码相同的文件夹下,以便于用户使用,只需下载文件夹压缩包即可立即使用。对于Paper++的目标用户,即高年级本科生、硕士、博士研究生、高校科研人员、企业科研人员等来说,个人阅读、学习中涉及到的论文数量相对较小,不需要为此专门将数据库存放于磁盘中特定的位置以提高读写速度。
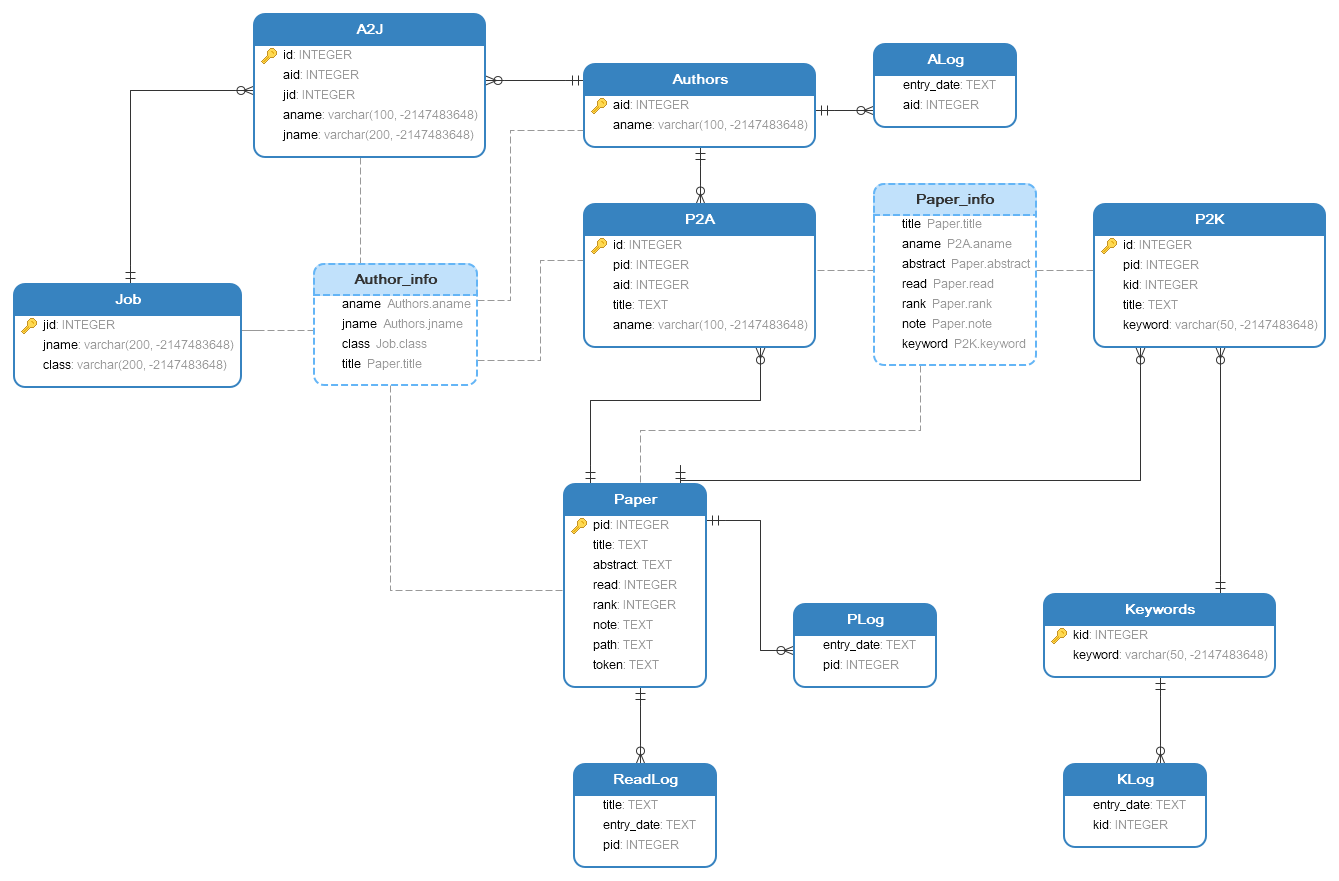
图3-3 Paper++数据库关系图
3.6 数据库实施
该部分所有代码均在实际SQLite语句上进行了必要化简和省略,详细代码见createTable.py, createView.py, createTrigger.py, createIndex.py四个文件。
3.6.1 表的定义
1 | Paper |
以下表格均为联系表或日志表,仅作简略展示。外键对应前面所述表中同名的属性。
1 | P2K (id, (pid, kid), title, keyword); |
3.6.2 视图的定义
1 | Paper_info |
1 | Author_info |
3.6.3 触发器的定义
以下三个触发器用于记录Paper,Keywords,Authors三个表的写入日志。NULL对应自增主键列,datetime(‘now’, ‘localtime’)用于获得时间。
1 | Paper_log AFTER INSERT ON Paper |
1 | Keyword_log AFTER INSERT ON Keywords |
1 | Author_log AFTER INSERT ON Authors |
Read_log触发器用于记录用户阅读论文,new.title用于获得当前用户正在阅读论文的题目,NULL对应自增主键列,datetime(‘now’, ‘localtime’)用于获得时间。
1 | Read_log AFTER UPDATE OF read ON Paper |
3.6.4 索引的定义
我在四个主要表上建立了索引,索引可以帮助我在查询时减少检索的时间。
1 | Paper_index ON Paper (pid) |
3.7系统实现和测试
3.7.1 模块流程图
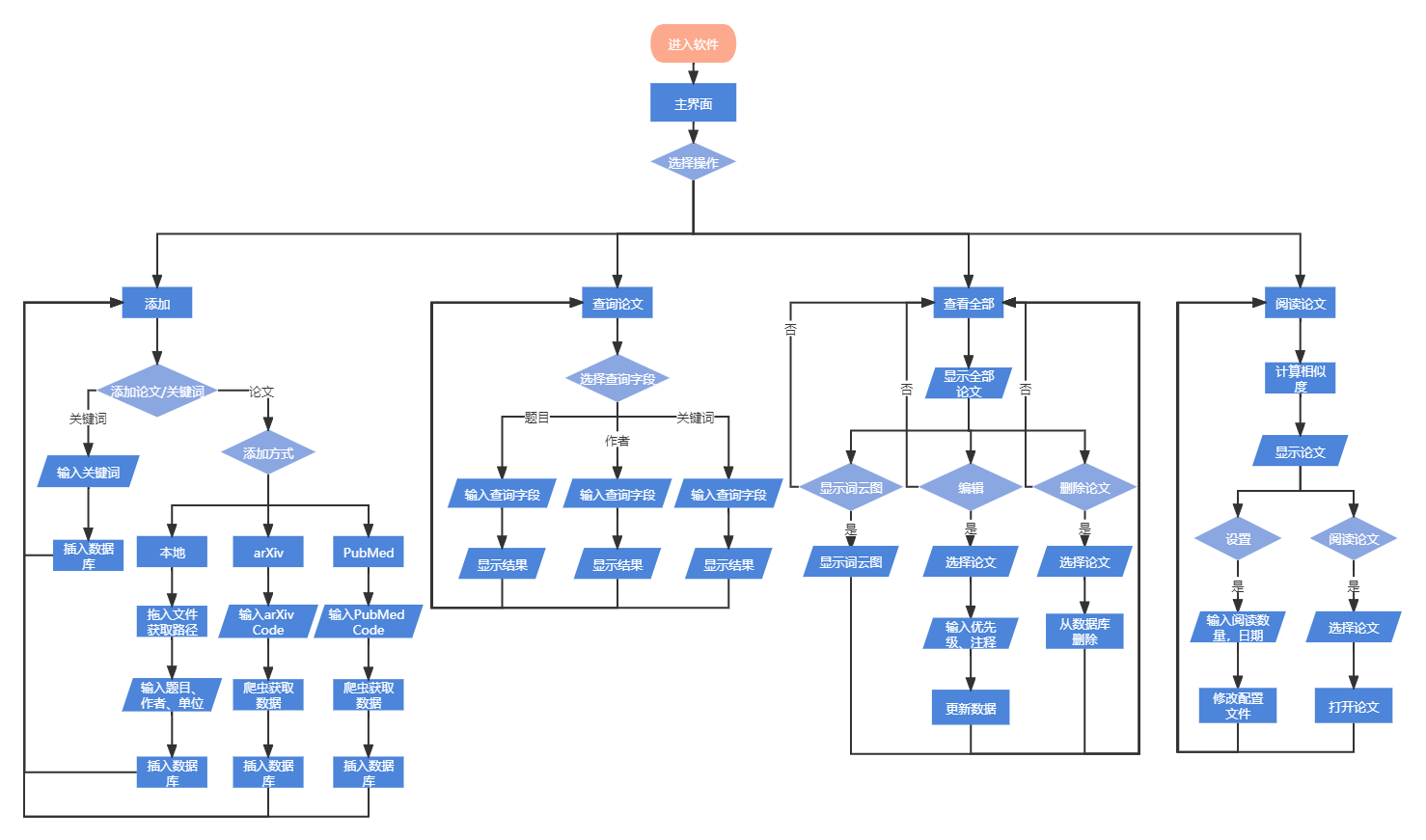
图3-4 Paper++模块流程图
3.7.2 开发环境
3.7.2.1 主要开发环境
Python==3.9.7
SQLite==3.35.5
sqlite3==(2, 6, 0)
PyCharm Community Edition 2020.2.1 x64
3.7.2.2 package
仅列出部分主要的Python包,详细内容见requirements.txt文件
beautifulsoup4==4.10.0
matplotlib==3.4.3
nltk==3.6.5
numpy==1.21.2
pandas==1.3.3
pdfminer3k==1.3.4
Pillow==8.3.2
requests==2.25.1
scipy==1.7.1
windnd==1.0.7
wordcloud==1.8.1
3.7.3 核心代码
- 插入一篇论文,修改涉及到的Paper表。修改Authors表、Job表的过程与此类似。
1 | with conn: |
- 插入一篇论文,修改涉及到的P2K表。修改P2A表、A2J表的过程与此类似。
1 | sql4 = "SELECT * FROM 'Paper' WHERE title = '{}';".format(title) |
- 用户设置论文阅读优先级,注释,更新Paper表
1 | def update(rank, note, title): |
- 从视图Paper_info中查询信息,使用Python中的set数据类型将其聚合。
1 | def get_sql_value(): |
- arXiv爬虫获取论文信息和下载论文,PubMed爬虫与之类似。
1 | class arxivSpider: |
- 插入关键词
1 | ExtractKeywords.init_db(self) |
- 主界面点击按钮打开添加论文界面,所有打开新界面的方法与之类似。
1 | def add_paper_clicked(): |
- 双击打开论文,并且将该论文的read属性改为1
1 | def treeviewclick(event, tree, paper_data): |
- 生成阅读论文界面按照优先级排序的索引,并计算相似度矩阵找到最相似的论文
1 | paper_data = np.array(paper_data) |
- 读取本地论文pdf文件,并进行处理
1 | def read_pdf(path): |
- 从预训练词向量中获取论文的特征向量token
1 | def open_w2v(): |
- 生成词云图
1 | keyword_ls = np.squeeze(keyword_ls) |
3.7.4 界面截图

图3-5 主界面

图3-6 添加论文界面
图3-7 读取本地论文小工具

图3-8 搜索界面

图3-9 搜索界面(按照题目搜索)
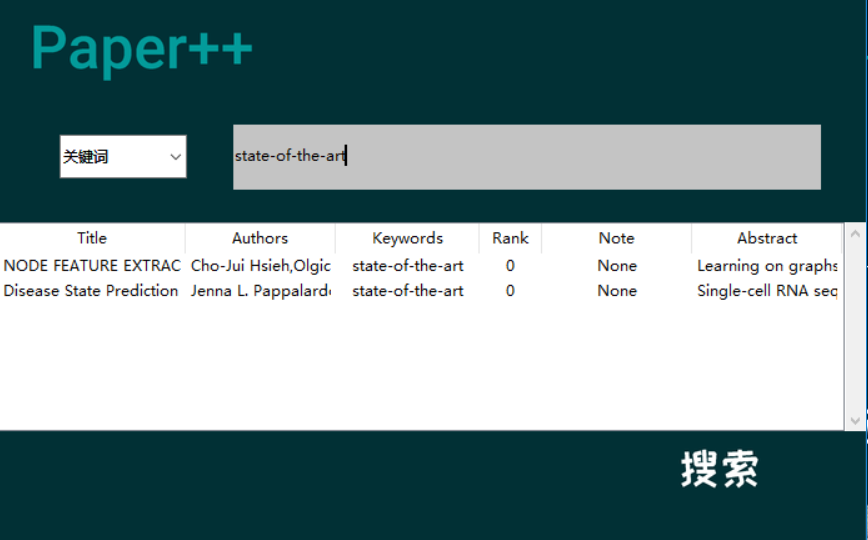
图3-10 搜索界面(按照关键词搜索)

图3-11 查看全部论文界面

图3-12修改论文优先级和注释

图3-13词云图
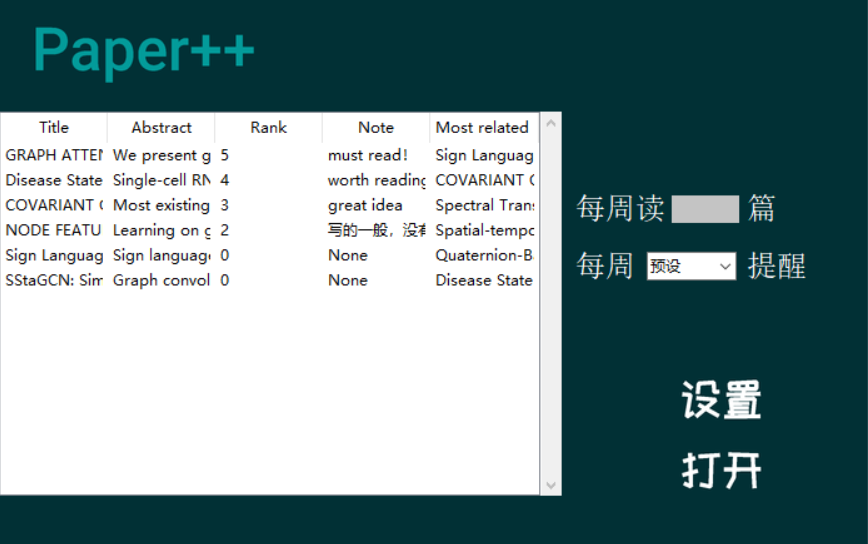
图3-14 阅读论文界面
3.7.5 需求分析
3.7.5.1 添加论文模块
实现了读取本地pdf文件,对信息进行处理,内容展示。对于arXiv和PubMed两个来源的论文,实现了相应的爬虫技术,从网页获取论文的信息并且下载论文。最后将论文信息插入数据库。实现了在此界面手动加入新的关键词,将新加入的关键词加入Keywords表。
3.7.5.2 展示全部论文
实现了从视图中查询数据,并且对数据进行整合,最终进行展示。实现了删除论文条目的按钮,程序清除数据库中对应表和与其相关的表中的信息。实现了弹出界面编辑、修改阅读优先级、阅读注释,以及点击按钮查看生成的关键词词云。
3.7.5.3 查询模块
用户可以对标题、作者、关键词三个字段进行查询,标题可以进行模糊查询。
3.7.5.4 阅读论文模块
实现了按照优先级生成未读的论文的列表,双击论文条目即可打开文件。计算论文相关性并展示与每一篇论文相关性最强的论文题目。
4 系统评价
4.1 系统特色
4.1.1 阅读文献的推荐。
阅读文献的推荐按照用户定义的优先级进行排序,同时会显示与其最相关的一篇论文的题目。将显示的论文按照用户定义的优先级排序只需要简单的调用函数即可,而显示最相关论文的功能则较为复杂,Paper++使用了深度学习自然语言处理的技术来实现这一功能。
Paper++采用word2vec模型的预训练词向量将文献关键词单词向量化,然后对文献涉及到的所有关键词词向量求和作为文献特征向量。将两篇文献的文献特征向量相减,对结果求二阶范数即可得到两篇文献的相似度。最后对所有文献两两进行相似性的衡量,构建相似度矩阵。将相似度矩阵的主对角线上的元素设为无限大(np.inf),对每一行求最小值即可得到最相似的论文。计算论文a和论文b之前相似性的公式如下:
$$
similarity(paper_a, paper_b) = ||(paper_a(\sum_i^{all}token_dict(keyword_i))- paper_b(\sum_i^{all}token_dict(keyword_i)) ||
$$
公式4-1 论文a和论文b之间的相似性
$$
\begin{bmatrix}
np.inf & … & similarity(paper_1, paper_n)\
… & \ddots & … \
similarity(paper_n, paper_1) & … & np.inf
\end{bmatrix}
$$
公式4-2 相似度矩阵
采用预训练的词向量主要是为了降低计算量,降低对设备的要求。预训练的数据来源: Glove[1] (6B tokens, 400K vocab, uncased, 50d, 100d, 200d, 300d vectors),Glove数据涵盖了40万英文单词的词向量,原始数据超过60亿单词。原始数据来自 Wikipedia 2014[2] + Gigaword 5[3] 。预训练数据包括50维,100维,200维,300维四组,我采用了50维的词向量。我并没有采用表示能力最强的300维词向量,这是因为在预训练的40万条词向量中查找对应单词的词向量需要比较大的计算量,在我的笔记本电脑上(Intel i7-8550U CPU @ 1.800GHz 1.99GHz)计算一篇论文的50维词向量需要大约30秒。
通过深度学习的技术,用户在阅读论文时会被推荐最相关的论文,便于用户的学术学习和整理探索。
4.1.2 SQLite数据库
由于SQLServer数据库对与Python的支持不好,所以我选择了SQLite数据库。
SQLite是一个轻量级的数据库,在内存中只有数百kb的占用,它能够支持Windows、Linux等主流的操作系统。更重要的是,SQLite在设计之初就是为嵌入式的使用,所以在Python中操作SQLite数据库非常的简单便捷
4.1.3 关键词词云图
统计关键词在所有论文中出现的词频,以词频为权重,借助Python中的wordcloud库实现词云图的绘制。通过词云图,用户可以清楚的看到当前归档的论文中学科、领域的偏重。
4.1.4 爬虫
输入网址,借助爬虫即可实现提取文献信息,文献自动下载。
Paper++使用了requests和beautifulsoup库实现了简单的爬虫,从网页上获取文献标题、作者、作者单位、摘要等信息。然后对这些信息进行整理和预处理,插入数据表中。如果需要,还可以自动从网页下载论文到本地。(由于网络原因,部分外网论文下载速度极慢,所以推荐用户自行下载论文。)
对于暂时无法使用爬虫获取信息的论文,用户可以自行下载pdf文献,将文件拖动导入Paper++中,Paper++会自动处理pdf文件,提取标题、作者、摘要等信息。
目前论文爬取支持的数据库网站有arXiv[4]和PubMed[5]。arXiv是由Cornell University 支持运营维护的一个非盈利的数据库,涵盖物理、数学、计算机科学、定量生物学、定量金融、统计学、电气工程与系统科学、经济学等领域。是世界上最大的论文预发表数据库。PubMed专注于医学、生物学等,收录了大量的论文。
4.1.5 文献关键词提取
自动从摘要中提取关键词,并加入数据库中。采用查字典的方式实现,数据表Keywords中保存着所有关键词和对应id,Paper++通过字符串匹配,从摘要中获取关键词Keyword,并加入记录论文相关信息的表中。
4.2 系统不足及改进
4.2.1 平台迁移
目前Paper++仅能在Windows桌面端使用,不支持mac OS系统,不支持移动端,且不支持远程访问等。下一步计划开发mac OS版本、安卓版本、ios版本,微信小程序版本,并且实现不同版本的互通。将用户的数据库信息存储在云端,使得用户无论何时何地,只要能连接互联网就能使用Paper++查看自己保存的文献资料。
4.2.2 爬虫功能扩展
目前Paper++仅支持arXiv和PubMed两个数据库,下一步计划扩展到更多数据库,并且使得Paper++支持通过DOI(digital object identifier)查询、下载论文。对所有论文爬虫进行整合,目前爬取论文信息需要事先选择数据库,整合后的论文爬虫不需要选择数据库网站,输入DOI号或者题目即可直接爬取。
4.2.3 论文阅读推荐功能扩展
目前Paper++获取文献特征向量采用的方式是将关键词的词向量求和作为文献的特征向量,这种方法计算难度较低,对设备要求低,而且可以采用预先训练好的词向量。但是文献特征向量受限于关键词的数量和关键词对文献信息的表示能力,这将极大的影响到文献特征向量的表示能力。下一步计划采用大型预训练语言模型,直接对文献全文进行表示,对比论文全文的相似度。同时引入推荐系统CTR等技术和内容,实现最优的论文推荐,
同时,结合下一步计划中爬虫的功能,Paper++可以实现对未归档文献的推荐。
5 设计心得
5.1 界面设计
用户界面对于程序来说是最重要的地方之一,用户使用软件首先见到的用户界面,所有的交互也都发生在用户界面上,如果用户界面设计的很粗糙,满满的“程序员风”,用户是不愿意持续使用这个软件的,于是我在用户界面上花了很大的精力。
我使用Python来进行数据库的嵌入式开发,同时由于我对于前端的框架并不是很了解,于是我就使用了Python中的Tkinter库进行界面的开发。为了做出优美、简洁的用户界面,我一方面开始学习Tkinter库,一方面在网上查找资料。我在GitHub上发现了一个开源的工具:Tkinter-Designer[6],这个工具可以将设计图直接转换成相关的Python代码,在我对其进行测试后,发现使用完全没有问题。但是其只支持按钮、文本框、显示图片等基本功能,对于较为复杂的显示列表、下拉菜单等功能则不支持。于是我使用了Figma[7]网页工具绘制界面设计图,然后使用Tkinter-Designer工具转换成Python代码,最后在此基础上自行加入一些复杂的功能。这样就实现了界面的制作。
5.2 Sqlite
在上学期的数据库课程中,我学习了SQLServer数据库的使用,代码的语法规则。但是在Python中对SQLServer的支持不好,所以我没有选择使用Python + SQL server的组合,而是使用了Python + SQLite3。在Sqlite3中,许多语句和使用方法都与SQLServer有一些细微的差别。这些语法上的不同在编写代码初期对我造成了一些困扰,随着我不断地学习和使用SQLite,这些都不再成为问题。
5.3 Python
在此之前,我对Python有一定的了解,于是选择了SQLite嵌入Python进行Paper++的开发。在实际开发中我仍然遇到了许多小问题,比如我经常把Numpy库的array对象和Python自带的list数据类型弄混,将二者的方法混合使用,这对于开发初期的我是一个极大的困扰,也在调试程序,修改bug上花费了大量的时间。随着开发的进行,这些小问题都不再成为我的绊脚石,我可以很轻松的写出代码,并且一次测试通过。
除了Python中我已经了解的知识,我还学习了许多新的知识,比如Tkinter库的使用,比如基础的计算机网络知识、爬虫的代码实现,比如单词词云图的制作和展示。这对我以后的学习、工作都有极大的帮助。
5.4 文本相似度
1. Paper++中提取关键词的方法较为简单,是词典+用户自行手动添加。如今NLP领域对于此问题已经有比较成熟的研究成果,如基于词典的正向/逆向最大匹配等方法。
1. Paper++中比较文本相似度的方法较为简单、基础,是比较关键词的word embedding作为文本的相似度。如今NLP领域对于此问题已经有了大量优秀的模型,比如ESIM,RE2,RSSM等。
下一步计划将更多前沿的NLP领域研究成果融入Paper++中。
参考资料:
[1] Glove https://nlp.stanford.edu/projects/glove/
[2] Wikipedia 2014 http://dumps.wikimedia.org/enwiki/20140102/
[3] Gigaword 5 https://catalog.ldc.upenn.edu/LDC2011T07
[4] arXiv https://arxiv.org/
[5] PubMed https://pubmed.ncbi.nlm.nih.gov/
[6] Tkinter-Designer https://github.com/ParthJadhav/Tkinter-Designer
[7] Figma www.figma.com/




