
Designs of C Programming
Designs of C Programming —— MNIST Handwritten Digit Recognition
MNIST Handwritten Digit Recognition
一. 题目意义和设计思想
1、题目意义
人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大,可以设想,未来人工智能带来的科技产品,将会是人类智慧的“容器”。人工智能可以对人的意识、思维的信息过程的模拟。人工智能不是人的智能,但能像人那样思考、也可能超过人的智能。
随着人工智能技术的发展,行业中里程碑式的成就AlphaGo一下引爆了人工智能这个话题,越来越多的人开始关注并投入到这个行业中。人们开始关注人工智能的发展和未来,许多与人工智能有关的话题在反复的被讨论着。
我的选题“手写数字识别”正是人工智能中较为基础,入门的应用之一。模型通过训练可以实现对人类手写数字(阿拉伯数字)的识别,无论数字写的工整还是潦草,方正还是歪斜,模型都可以进行识别,并达到85%的准确率。
2、设计思想
手写数字识别已经成为了机器学习与深度学习领域重要的入门程序,网上也有很多人用不同的编程语言,不同的模型,不同的模型结构的实现。我也曾使用Python语言和Tensorflow下的Keras框架实现过七层卷积神经网络来解决本问题,准确率达到99.9%以上。我在本次大作业中我采用了两层的全连接神经网络,使用MNIST数据集的二进制格式文件作为输入,准确率达到85%。MNIST数据集是手写数字识别问题中最流行的数据集,包含的图片为28 * 28像素的灰度图片,即每个像素点使用0~255的数字代表颜色深浅。
相比于使用Python编写程序,本次程序的编写主要有两个不同。
第一点是C语言中较为底层,并没有像Tensorflow、Pytorch、Opencv这样方便的深度学习框架,我复习了相关知识的原理并且将问题进行简化。我将图片信息展平成序列作为输入,并没有使用处理图像问题通用的卷积神经网络,将对图片的预测问题转化为普通的人工神经网络。
第二点是C语言无法有效的读取Excel的csv文件,通过查找网络,我找到了可以用C语言程序读取的MNIST数据集的二进制版本,并学习了相关文件的读取使用方法,使用位运算将二进制数据转化为十进制。
此外,为了锻炼自己的工程能力,我将程序拆解为了几个部分分别写入不同的文件中,并使用头文件的形式在主程序调用相关函数。并且严格按照工程应用的标准来要求自己,在变量名定义、撰写注释等细节上反复修改。
二、采用的主要技术、遇到的难点和解决方法
本程序采用了两层的全连接人工神经网络,包含输入层和输出层。输入层共有784 (28*28)个神经元,对应图片展平后的每一维数据,输出层包括10个神经元,对应0~9共10个阿拉伯数字。输入数据为60000张图片,测试数据为10000张图片,所有数据均来自MNIST数据集。模型使用了反向传播算法,激活函数为线性函数,使用梯度下降(Gradient Descent)优化方法,并对输出进行了归一化。
由于我对神经网络较为熟悉,所以相关的内容并没有成为我的“拦路虎”,本次程序的难点主要在三个方面:
第一个方面是读文件。由于我从来没有处理二进制文件的经验,相应的知识也并未在课堂上讲授,我通过网络学习了相关文件的读取处理方法,并使用位运算进行处理数据,使其变为我熟悉的十进制数据。
第二个方面是在图片和训练的展示上。经过探索,我将原本灰度图片中所有灰度值不为0(纯黑色)、255(纯白色)转化为0和255。由于本问题仅仅用于识别单个的数字,这样的转换基本不影响最终结果而且更为方便。用 .表示白色,用X表示黑色,实现了图片的简单展示。
第三个方面是使用工程应用的代码风格。让我下定决心这么做的原因是一次小小的事故。当我完成了部分代码的编写后在编写主程序的过程中发现自己已经弄不清各个函数和变量的含义,一开始我在编写程序中使用的是首字母缩写作为变量和函数名,而且没有写注释,时间一久,内容一多就很难区别。于是我在网上查找了工程应用中严谨的代码风格,按照要求对我的程序进行了改写,并且加上全面详尽的注释。我在这个过程中也学习了不少计算机专业的英文单词。
三、实现的主要功能和系统结构
功能:输入手写阿拉伯数字的图片,做出预测,输出数字的内容,将图片简单的进行展示,最后计算预测准确率。
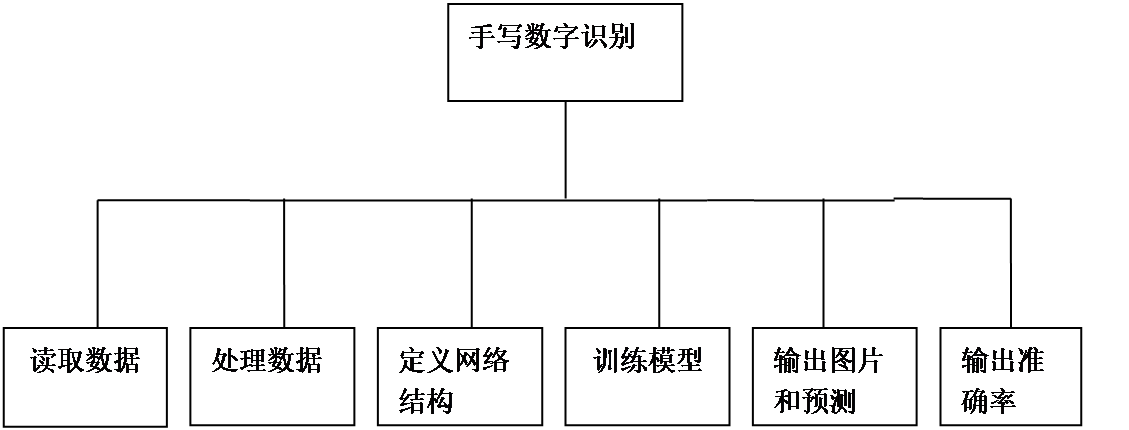
程序构成
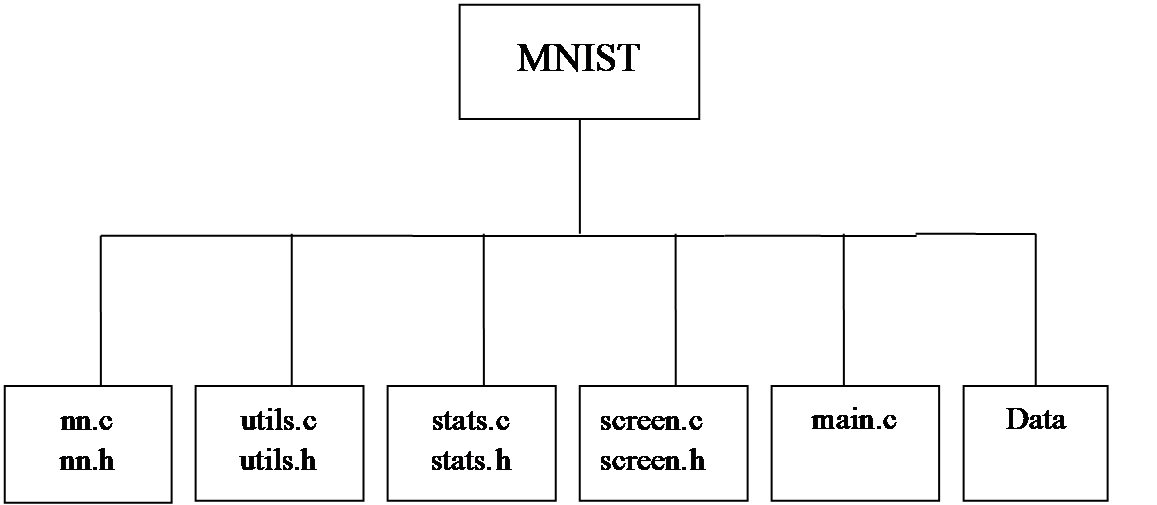
文件构成
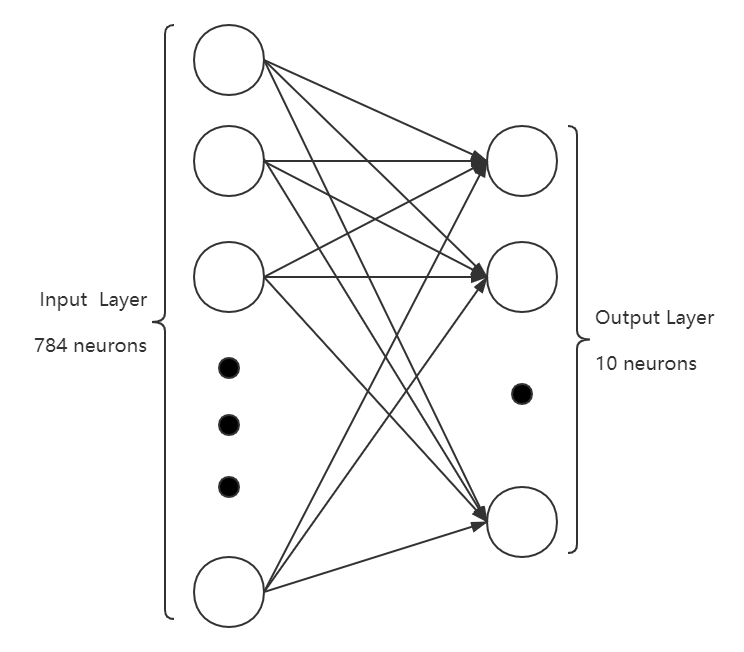
神经网络结构
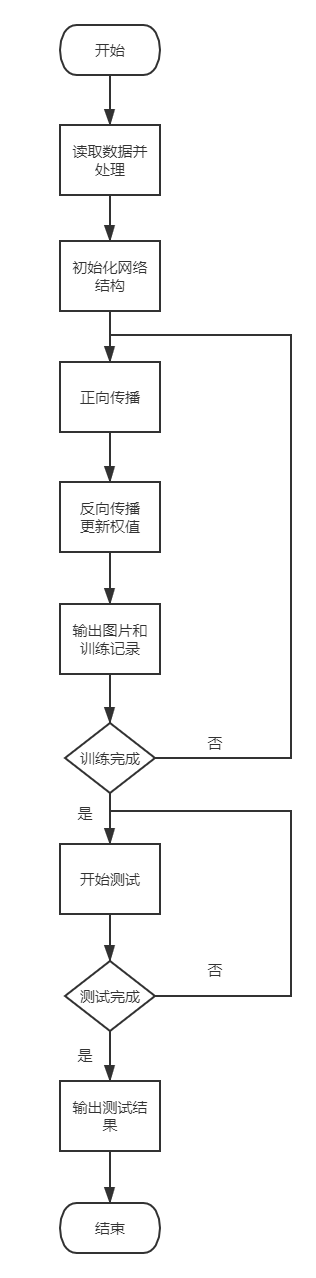
流程图
四、核心算法描述和相关技术说明
核心技术为人工神经网络,使用反向传播算法(BP算法),并辅助有数据预处理等。
1. 反向传播算法
BP算法最早出现在20世纪60年代,30年后由大卫·鲁梅尔哈特、杰弗里·辛顿和罗纳德·威廉姆斯在1986年的著名论文中推广。在这篇论文中,他们谈到了各种神经网络。今天,反向传播做得很好。神经网络训练是通过反向传播实现的。通过这种方法,我们根据前一次运行获得的错误率对神经网络的权值进行微调。正确地采用这种方法可以降低错误率,提高模型的可靠性。利用反向传播训练链式法则的神经网络。简单地说,每次前馈通过网络后,该算法根据权值和偏差进行后向传递,调整模型的参数。典型的监督学习算法试图找到一个将输入数据映射到正确输出的函数。反向传播与多层神经网络一起工作,学习输入到输出映射的内部表示。
反向传播算法的流程如下:
输入层接收x
使用权重w对输入进行建模
每个隐藏层计算输出,数据在输出层准备就绪
实际输出和期望输出之间的差异称为误差
返回隐藏层并调整权重,以便在以后的运行中减少此错误
一直重复这个过程,直到我们得到所需的输出。训练阶段在监督下完成。一旦模型稳定下来,就可以用于生产。
2. 数据预处理
本模型中使用的数据预处理较为简单,是根据目标的特色而专门设计的预处理方式,即:将训练和测试数据集中的样本灰度图中灰色的像素划分成黑色或者白色,划分依据为灰度值的大小,距离白色(255)更近就化为白色,距离黑色(0)更近就化为黑色。
五、总结和体会
这次大作业给我的收获非常大,让我从之前一知半解的“调包侠”逐渐向着真正的人工智能工程师转变。用更为底层的语言解决问题使得我去反复思考学习算法和模型结构的基础原理。并且根据实际情况做出应变和处理。比如我为了寻找符合C语言的文件输入采用了二进制的方法,为了简化过程,提高准确率做了数据预处理.
未来我希望能够使用C语言完成更多模型的编写,包括但不限于决策树,支持向量机,高斯混合模型等。并且扩充改造本模型,尝试完成卷积神经网络,池化,dropout等处理。
最后,本次大作业更加坚定了我要持续在这个领域学习,研究的信念。希望未来能够在这个领域有所建树,真正的为了人类的发展做出微薄的贡献。



